Searching WorldCat indexes guidelines and requirements
Browsing
Browsing scans an index with the intent of finding a matched term or the closest matching term, rather than retrieving records. Selecting a term in a browse results list then retrieves the relevant record(s).
Each index description notes whether the index supports searching only or both searching and browsing.
Browse WorldCat using either:
- A word that appears anywhere in indexed fields and subfields.
- An exact phrase (complete subfield) or whole phrase (complete field), starting with the first word and including all words (but excluding initial articles in titles). The phrase you enter is matched character by character, from left to right, against the characters of the phrase in the index you specify.
The system returns a list of terms showing a match or the closest match, along with terms that precede and follow the matching term. When you open an entry on the list, you see the record or a list of records retrieved for that term.
Capitalization
Index labels and search terms can be upper- or lowercase or a combination.
Default index
If you do not include an index label, the system uses the Keyword index (kw:) as the default.
Derived searches
Derived searching reduces the number of keystrokes you enter.
A derived search uses a specific number of initial characters from sequential words in a name or title.
- The "derived" segments of the words are separated by commas.
- A word is defined the same as for keyword searching (any character(s) between two blank spaces).
- The number and pattern of letters and commas tells the system which derived index to search.
- In a Connexion command line search or a FirstSearch expert search, using the derived search index label and punctuation is optional if it is the first or only element of the search. Always use index labels and punctuation when combining a derived search with a search in a different index.
Initial articles (such as "a", "an", and "the")
Internet URLs and the 856 field
When searching for Internet URLs in relation to the 856 field, use mt:url to see if the 856 field exists in an Internet-only resource. It is also possible to search mt:web to retrieve any record with any kind of 856 field. Also, see Access Method for information about searching URLs and the 856 field.
Levels of searching
To give flexibility in search strategy and control over the results, OCLC provides various levels of searching, from simplified to complex.
Examples of searches in this guide are given in full search syntax (most complex format). From full syntax examples, you can extrapolate the parts of a search you would enter or select in boxes and lists to construct a basic or guided form of the search.
Non-Latin/non-Roman scripts
The Connexion client and FirstSearch interfaces support all UTF-8 Unicode defined characters for non-Latin script search terms, which includes the following non-Latin, MARC-8 scripts: Arabic, Chinese, Cyrillic, Greek, Hebrew, Japanese, and Korean, as well as all of the UTF-8 Unicode character sets. For a complete list of supported scripts, see the Unicode character code charts.
Modern Standard Arabic
WorldCat Discovery allows you to search and sort using Modern Standard Arabic.
Diacritics
WorldCat Discovery returns the same results regardless of whether users enter search terms with or without diacritics such as hamza “ء” or madda “آ”. For example, we treat the following as equivalent:
- “ى” and ”ي”,
- “ه” and ” ة ”
- “آ” “ا” “إ” “أ”
Definite articles and prefixes
For title searches, results are the same with or without preceding definite articles or prefixes. For example:
- Definite articles are dropped: “ال“
- Prefixes are ignored: “ب” “ك” “ف” “لل”
Kashida
WorldCat Discovery treats characters the same whether elongated or not. For example:
- With kashida: “مـديـنــــــــــــــــة “
- Without kashida: “مدينة”
Standard Thai
WorldCat Discovery allows you to search and sort using Standard Thai.
Normalization
Normalization is not applied to any Thai indexes. All Thai vowel symbols and diacritics are treated as significant and never ignored.
- Exception: Characters with tone marks: composed/decomposed
Thai characters that have tone marks in both composed and decomposed forms are indexed.
Example:

When entered in composed form in a search term, the character will match both composed and decomposed forms in the index and vice versa. If searched in decomposed form it will match both the decomposed and composed form.
Tokenization
Because Thai script phrases are written without spaces between words, to recognize and index individual Thai words, tokenization is applied to build all Thai word indexes and to parse word index queries. We do not apply tokenization for phrase indexes or phrase index queries.
Indexing of individual Thai words enables word index searching whereby records containing the query terms anywhere in the appropriate indexed fields are retrieved.
|
|
Thai |
English translation |
|---|---|---|
|
Query |
ti:สนทนาภาษาจีน |
Chinese conversation |
|
Tokenized query |
· สนทนา · ภาษา · จีน
|
· talk/converse · language · China |
|
Matching record title |
สนทนา 3 ภาษา ไทย-อังกฤษ-จีน โต้ตอบอย่างมั่นใจ พิชิตงานบริการในโรงแรม |
Conversation in three languages: Thai-English-Chinese. Respond confidently and conquer service jobs in hotels. |
|
Tokenized record title |
สนทนา 3 ภาษา ไทย อังกฤษ จีน โต้ตอบ อย่าง มั่นใจ พิชิต งาน บริการ บริการ_ใน ใน ใน_โรงแรม โรงแรม |
Talk/Converse 3 language Thai England China respond at/manner confident conquer work service service_in in in_hotel hotel |
Common words
Referring to the list of common Standard Thai words below, rather than treating them as stop words whereby they would be ignored for indexing and matching, we combine them with adjacent words when we build word indexes and parse word index queries.
When a common Thai word is ignored (treated as a stop word), an adjacent word that remains can have a different meaning than when combined with/adjacent to a common word. This different meaning can lead to the retrieval of irrelevant records. In cases where the meaning of a word would have changed had we removed the adjacent common word, combining it with the adjacent common word helps to disambiguate its meaning, providing greater search precision by reducing retrieval of irrelevant records.
We apply the above processing of common words when building and searching the following indexes:
- se: Series
- ti: Title
- kw: Keyword
Common word treated as a stop word
- Query ti:มาตราการ (measures/procedure)
- Tokenized into มาตรา and การ
- The common word การ is removed as a stop word leaving only มาตรา
- มาตรา has a different meaning (section or clause of law) from มาตราการ (measures/procedure) and therefore retrieves records that are not relevant to the query ti:มาตราการ
Common word combined with an adjacent word
- Query ti:มาตราการ (measures/procedure)
- Tokenized into มาตรา_การ (because การ is defined as a common word)
- Records with title fields containing มาตราการ
- Titles are tokenized into มาตรา มาตรา_การ การ
- Only records containing มาตราการ are retrieved.
Thai common word list:
|
กว่า กับ การ ก็ ขณะ ของ ความ คือ จะ จึง |
ซึ่ง ด้วย ตั้งแต่ ต่างๆ ถึง ถ้า ทั้ง ทั้งนี้ ที่ นั้น |
นี้ ว่า หรือ หาก อะไร อาจ อีก เช่น เนื่องจาก เป็นการ |
เพื่อ เมื่อ เลย เอง แต่ และ แล้ว โดย ใน ไว้ |
Sort
We sort Standard Thai author, title, and call number fields using the default collation order of the Unicode collation algorithm that we apply for all scripts and languages.
Alphabetical sorting is available in WorldCat Discovery when using the following features:
Sort search results:
- Author (A-Z)
- Title (A-Z)
The Author search filter expanded to show more:
- The Author search filter initially displays authors sorted by matching record count, highest first. Selecting the Show More option to expand the filter sorts the authors alphabetically.
- If the expanded and alphabetically sorted view includes author names in multiple scripts, names in Latin script are presented first followed by those in other scripts.
Browse the Shelf from the item details page:
- Browse the Shelf uses sorting of call numbers. Call number sorting commonly differentiates items with the same call number using an alphabetical suffix. Thus, QV772 ร451 would sort before QV772 ล148ย because ร sorts before ล.
Search for local holdings record (LHR) data
The following table outlines the data elements and fields available to search for LHR data in Connexion, FirstSearch, WorldShare, and WorldCat Discovery.
Spacing
In all searches, do not enter spaces between the index label and punctuation or between punctuation and the search term. Example: kw:software
Special characters in Latin script searches
The following table of punctuation, diacritics, and special characters describes how to treat each character when you construct WorldCat search or browse terms.
- Special characters in Latin script searches - Table
-
Name Character How to treat in search and browse terms æ or Æ 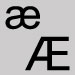
Substitute the letters ae. Acute 
Omit and close up the space. Alif/modifier letter right half ring 
Omit and close up the space. Almost equal to 
Omit and leave a space. Ampersand 
Type. Apostrophe 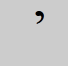
- Omit and close up the space.
- Omit from word searches. Words preceded by single letter c, d, j, l, m, n, s, or t and an apostrophe are not yet normalized in the system (that is, not indexed together so that a search term with or without the character retrieves the same records). For now, enter both forms combined with OR to retrieve all appropriate records. For example, to search for l'etranger, enter etranger or letranger.
- Omit from Dewey class number searches; however, if Dewey class numbers contain slashes, the system indexes them both with and without data following the slashes. For example, 123.45/67/89 is indexed as 123.45 and 123.4567 and 123.456789.
Asterisk 
Omit and leave a space. At sign 
Omit and leave a space. Ayn 
Omit and close up the space. Backslash 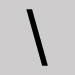
- Omit and leave a space.
- Type in an access method phrase search.
Brackets and bracketed information 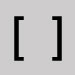
Omit and close up the space.
- Omit opening and closing brackets and close up the space.
- Omit brackets and data within the brackets in these two cases:
- [sic]
- [i.e. and any following data]
- Otherwise, include data within brackets in searches.
Breve 
Omit and close up the space. British pound 
Omit and leave a space. Candrabindu 
Omit and close up the space. Cedilla 
Omit and close up the space. Circle above letter (angstrom) 
Omit and close up the space. Circle below letter 
Omit and close up the space. Circumflex, spacing or nonspacing 
- Omit and close up the space, except include spacing circumflex in URLs.
- Add to some types of derived searches for greater precision.
Colon 
Omit and leave a space. Combining double grave accent 
Omit and close up the space. Combining retroflex hook below 
Omit and close up the space. Combining inverted breve below 
Omit and close up the space. Combining macron below 
Omit and close up the space. Comma 
- Omit and leave a space. Some exceptions are:
- Omit and close up the space if the comma is preceded and followed by a number.
- Include the first comma in a name phrase or whole phrase search (indexes that include 100 a and 700 a), if it is not the last comma in a subfield.
- Use to separate the parts of a derived search.
Copyright sign 
Omit and close up the space. Crossed d 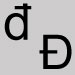
Substitute the letter d. Curly brackets 
Omit and close up the space. Dagger 
Omit and leave a space. Degree sign 
Omit and close up the space. Delimiter 
Omit, along with the single letter or number following it, and leave a space. Division sign 
Type. Dollar sign 
Omit and leave a space. If used as a delimiter, also omit the single letter or number following it. Dot below letter 
Omit and close up the space. Double acute 
Omit and close up the space. Double dot below letter 
Omit and close up the space. Double tilde, first and second half 
Omit and close up the space. Double underscore 
Omit and close up the space. Downwards arrow 
Omit and leave a space. Equal sign 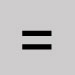
- Omit and leave a space.
- Use to precede a derived corporate name search, but only if index label is not used.
Eszett 
Enter eszett, or enter a double s: ss. Eth 
Substitute the letter d. Euro 
Omit and leave a space. Exclamation point 
Omit and leave a space. Feminine ordinal indicator 
Substitute the letter a. Grave, spacing or nonspacing 
Omit and close up the space, except include spacing grave in URLs. Greater than or equal to 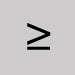
Omit and leave a space. Greater than sign 
Omit and leave a space. Hacek 
Omit and close up the space. High comma center 
Omit and close up the space. High comma off center 
Omit and close up the space. Hooked o 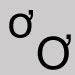
Substitute the letter o. Hooked u 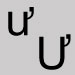
Substitute the letter u. Hyphen (minus sign) 
Omit and leave a space. Icelandic thorn 
Substitute the letters th. Infinity 
Omit and leave a space. Integral 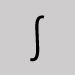
Omit and leave a space. Inverted (right) cedilla 
Omit and close up the space. Inverted exclamation point 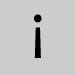
Omit and close up the space. Inverted question mark 
Omit and close up the space. Latin capital letter ENG 
Substitute the letter n. Latin capital letter ETH 
Substitute the letter d. Latin capital letter EZH 
Substitute the letter z. Latin capital letter G with stroke 
Substitute the letter g. Latin capital letter H with stroke 
Substitute the letter h. Latin capital letter L with middle dot 
Substitute the letter l. Latin capital letter T with stroke 
Substitute the letter t. Latin script letters 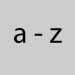
Type in upper- or lowercase. Latin small letter eng 
Substitute the letter n. Latin small letter ezh 
Substitute the letter z. Latin small letter g with stroke 
Substitute the letter g. Latin small letter h with stroke 
Substitute the letter h. Latin small letter kra 
Substitute the letter q. Latin small letter l with middle dot 
Substitute the letter l. Latin small letter long s 
Substitute the letter s. Latin small letter t with stroke 
Substitute the letter t. Left hook 
Omit and close up the space. Left right arrow 
Omit and leave a space. Leftwards arrow 
Omit and leave a space. Less than or equal to 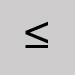
Omit and leave a space. Less than sign 
Omit and leave a space. Ligature, left and right 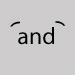
Omit and close up the space. Macron 
Omit and close up the space. Masculine ordinal indicator 
Substitute the letter o. Miagkii znak 
Omit and close up the space. Micro sign 
Omit and leave a space. Middle dot 
Omit and close up the space. Multiplication sign 
Type. Not equal to 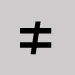
Omit and leave a space. Not sign 
Omit and leave a space. Number sign 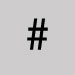
Omit and leave a space. Note: WorldShare and WorldCat Discovery automatically search #searchword as searchword (e.g., #girlboss is searched as girlboss).
Numerals 
Type. œ or Œ 
Substitute the letters oe. Parentheses 
Omit and close up the space. Use only when nesting Boolean searches. Patent mark/subscript patent mark 
Omit and leave a space. Percent sign 
Omit and leave a space. Period (decimal point) 
- Omit and close up the space for derived searches.
- Omit and leave a space in word searches except when numbers precede and follow the period.
- Type the first period in a class number search.
Phonogram copyright 
Omit and close up the space. Pilcrow sign (paragraph sign) 
Omit and leave a space. Plus sign 
- Omit in word searches.
- Include in phrase and whole phrase searches.
Plus/minus sign 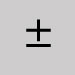
Omit and leave a space. Polish L 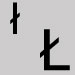
Substitute the letter I (ell). Pseudo question mark 
Omit and close up the space. Question mark 
Omit and leave a space. Quotation marks 
- Omit and leave a space.
- Use to enclose multiple words in a word search to retrieve the exact sequence of the words.
Right hook 
Omit and close up the space. Rightwards arrow 
Omit and leave a space. Scandinavian o 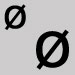
Substitute the letter o. Script L lowercase 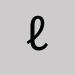
Substitute the letter l (ell). Section sign 
Omit and leave a space. Semicolon 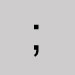
Omit and leave a space. Slash 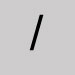
- Substitute a space.
- Omit and close up the space in number searches and in derived searches.
- Include as a prefix to "slash" qualifiers.
- Omit from Dewey class number searches; however, if Dewey class numbers contain slashes, the system indexes them both with and without data following slashes. For example, 123.45/67/89 si indexed as 123.45 and 123.4567 and 123.456789.
Space 
- Close up multiple adjacent spaces to one space.
- Omit leading and trailing spaces.
Square root 
Omit and leave a space. Subfield delimiter (See delimiter). Subscript minus sign 
Omit and leave a space. Subscript numerals 
Substitute the numbers 0 - 9. Subscript parentheses 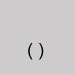
Omit and close up the space. Subscript plus sign 
Omit and leave a space. Superior dot 
Omit and close up the space. Superscript minus sign 
Omit and leave a space. Superscript numerals 
Substitute the numbers 0 - 9. Superscript parentheses 
Omit and close up the space. Superscript plus sign 
Omit and leave a space. Tilde, spacing and nonspacing 
Omit and close up the space, except include spacing tilde in URLs. Turkish i 
Substitute the letter i. Tverdyi znak 
Omit and close up the space. Umlaut (dieresis) 
Omit and close up the space. Underscore, spacing and nonspacing 
Omit and close up the space, except include spacing underscore in URLs. Up down arrow 
Omit and leave a space. Upandhmaniya 
Omit and close up the space. Upwards arrow 
Omit and leave a space.
Stemming
Note:
- This feature is not enabled in Connexion, FirstSearch, and WorldShare Collection Manager query collections.
- This feature works with keyword searches only.
Stemming is where each term in a query is treated as a logical OR of the various word forms of the term, so that all records that contain the alternate word forms are included in the result set. For example, the query acceleration would be treated as if it were acceleration OR accelerations OR accelerating.
| Search in WorldCat Discovery | Search type | Stemming Applied | Equivalent to Searching |
|---|---|---|---|
| acceleration | keyword | Yes | acceleration OR accelerations OR accelerating |
| kw:acceleration | keyword | Yes | acceleration OR accelerations OR accelerating |
| "acceleration" | exact phrase | No | acceleration |
| kw: "acceleration" | exact phrase | No | acceleration |
Stop words
Stop words (also called Common word exclusions) are common words that the system ignores in some types of searches. You can omit them from search items. To use any of these words as search terms, enclose them in quotation marks.
Stop words in WorldShare and WorldCat Discovery
The lists of stop words in WorldShare and WorldCat Discovery are specific to the following indexes:
Stop words in Connexion, FirstSearch, and WorldShare Collection Manager query collections
The list of stop words in Connexion, FirstSearch, and WorldShare Collection Manager query collections is specific to the following text-rich indexes: