Catalog using Chinese, Japanese, and Korean (CJK) scripts
Overview
Cataloging
Use CJK script data to catalog items in Chinese, Japanese, and Korean. Use CJK script data the same way you use other non-Latin script data in the client.
See Work with international records and Guidelines for contributing non-Latin script bibliographic records to WorldCat for details specific to non- Latin scripts. See also general procedures describing how to:
Authorities
CJK scripts can also be used to add variant name headings to authority records.
Tools for using non-Latin scripts
Specific tools for using CJK scripts
- CJK E-Dictionary to help with entering CJK characters: (Tools > CJK E-Dictionary).
- Automatic converter for converting invalid characters to equivalent MARC-8 characters (Edit > MARC-8 Characters > Convert to MARC-8 CJK).
Other tools to help with non-Latin scripts in general
- MARC-8 character verification (Edit > MARC-8 Characters > Verify) - Verify characters separately from record validation
- Link/unlink (Edit > Linking Fields > Link [or Unlink]) - Visually link or unlink non-Latin script data fields with equivalent Latin script (romanized) data fields (bibliographic records only)
- Export options for data fields (Tools > Options > International) - Determine (for bibliographic records only):
- Whether to export both equivalent Latin script (romanized) data and non-Latin script data or only one or the other
- Position of data if you export both Latin and non-Latin script data
- Sort order
- Export and import using UTF-8 Unicode or MARC-8 character sets. The UTF-8 Unicode option allows you to work with non-MARC-8 characters in the client for your local records (settings for export are in Tools > Options > Export, click Record Characteristics, and settings for import are in File > Import Records, click Record Characteristics).
- See more specific procedures for working with these tools.
CJK entry and character set
Script entry method
If your system default language is not the one you want to use for cataloging Chinese, Japanese, or Korean materials, you can install the languages you need. Windows provides the Input Method Editors (IMEs) appropriate for CJK character entry. See more about input methods for languages that use non-Latin scripts.
Character sets supported
The client supports the following Chinese, Japanese, and Korean character set defined in MARC 21 Specifications for Record Structure, Character Sets, and Exchange Media.
- 31(hex) [ASCII graphic: 1] = Chinese, Japanese, Korean (East Asian Coded Character set, or EACC)
EACC is the code used for storing CJK characters and linking them to related variants for indexing in the OCLC system.
Script identifier in bibliographic records
The client adds the following data to c of field 066 in CJK records to indicate the presence of CJK characters:
- $1
Entering punctuation
- OCLC suggests using the English keyboard to enter punctuation in CJK data fields.
- You may enter CJK punctuation marks using one of the CJK Input Method Editors only if the marks are in the MARC-8 character set (EACC) (see a list of input codes).
- For searching purposes, CJK punctuation and Latin punctuation are normalized; that is, you can enter punctuation either way and find the same records.
CJK E-Dictionary
Open the CJK E-Dictionary, an electronic dictionary, from the Tools menu. The CJK dictionary:
- Lets you search or browse to retrieve information about a single character, a group of related characters, homophones matching a phonetic inpurt code, or a large set of characters in sequence by East Asian Character Code (EACC) or by Unicode value.
- Shows comprehensive types of representation for each CJK character supported in Connexion client. Open an entry in the E-Dictionary to copy a value and paste it into a record, workform, constant data, or text string.
Convert invalid CJK characters to equivalent MARC-8 characters
When you verify CJK characters as MARC-8-compliant (Edit > MARC-8 Characters > Verify), and the client identifies invalid character(s), you can automatically convert the character(s) in the record to MARC-8-equivalent CJK characters:
- Click Edit > MARC-8 Characters > Convert to MARC-8 CJK or press <Alt><E><8><J>. The client converts the characters and changes the color of converted characters to green (by default) or to a color you specify in Tools > Options > Record Display.
If you already know that a record contains invalid CJK characters, you can use the Edit > MARC-8 Characters > Convert to MARC-8 command without first using the Edit > MARC-8 Characters > Verify command.
Note: The Library of Congress also has a CJK Compatibility Database on the Cataloging Policy and Support Office (CPSO) home page to help with MARC-8 compliant or missing characters.
Use the Chinese, Japanese, or Korean client interface
Change the interface language from English to Chinese (simplified or traditional), Japanese, or Korean. Select the interface language when you:
- Install the Connexion client for the first time.
- Open a new user profile you created based on a profile for which you have not already set the interface language.
- Change the interface option anytime in Tools > Options > International.
Note: To display the Chinese, Japanese, or Korean interface, you must have an input method for the language installed on your workstation (see Input methods for languages that use non-Latin scripts), or you must have a Chinese, Japanese, or Korean language version of Windows.
Indexing for CJK script searches
For CJK script searches, the system indexes both single characters and immediately adjacent characters in a field. Use the following search strategies:
- Word search - Enter an index label and a colon (for example ti:) followed by a character string with no spaces to find a single word, or followed by more than one character string separated by a space to find multiple words, anywhere in an indexed field.
- Phrase search - Enter an index label and an equal sign (for example, ti=) followed by a character string to find exact occurrences, starting with the first character in an indexed field and including each succeeding character. Truncate the character string to find the string followed by any other data without having to enter the entire data string as it appears in a field or subfield.
Note: To truncate, enter an asterisk (*) at the end of the search string. Enter a minimum of three CJK characters before truncating. - Phrase browse - Enter the Scan command, an index label, and an equal sign (e.g., sca ti=) followed by a character string. Phrase browsing scans an index for occurrences of the browse string at the beginning of indexed fields, followed by any other data (automatic truncation).
Note: Since all MARC-8 CJK characters are indexed singly, if you browsed for a word, the system would scan for the first character only, and results would not be significant.
Notes on searching
- If you use qualifiers to limit a search, type them using Latin script.
- Do not use derived searching.
- For searching purposes, CJK punctuation and Latin punctuation are normalized; that is, you can enter punctuation either way and find the same records. If you enter CJK punctuation, the characters must be in the MARC-8 character set (EACC) (see a list of input codes).
- If you want to retrieve all CJK script records or see sample records, use the Character Sets Present search index (label vp:) with the assigned code cjk.
- To find all CJK script records, enter vp:cjk as a Command Line Search only.
Note: If a search for all CJK script records alone retrieves too many WorldCat records (limit 1,500 records), you must limit the search and try again (e.g., vp:cjk/1991-2; vp:cjk and mt:bks; etc.).
- To find all CJK script records, enter vp:cjk as a Command Line Search only.
See general procedures and search techniques for searching WorldCat.
What is Tsang-chieh (TC) input code?
Definition
- 1 to 5 Latin script letters assigned to represent significant graphic elements of a Chinese character.
- Provides a unique code for each character.
- Can be used as a qualifier with a phonetic input code.
Basics
To use the TC input code, you must know graphic elements of characters, Latin script letters used to represent the graphic elements (see chart below), and rules for selecting significant graphic elements to code (see section below).
Latin script letters assigned to graphic elements

TC rules for coding
- Type the sequence of code letters based on the following visual characteristics of the character, not based on the stroke order in which the character is written:
- Top to bottom
- Left to right
- Outside to inside
- Determine whether the character is simple or compound and determine the number of significant graphic elements.
Code for a simple character or a compound character segmented by head (outermost, uppermost, or leftmost TC graphic element) and body (remaining graphic elements):Simple character Compound character Head Body 1-4 significant graphic elements: Enter a code letter for each.
5 or more elements: Enter a code letter for each of the first 3 and the last.1-2 elements: Enter a code letter for each.
3 or more elements: Enter a code letter for the first and last.1-3 elements: Enter a code letter for each.
4 or more (simple body): Enter a code letter for the first 2 and the last.
4 or more (compound body with subhead and subbody):- Subhead 1 - Enter a code letter for the first and last elements of the subhead and a letter for the first and last elements of the subbody.
- Subhead 2 or more - Enter a code letter for the first and last elements of the subhead and a letter for the last element of the subbody.
- Follow these guidelines to code:
- Simplicity - Minimize the number of graphic elements. Choose the letter that represents the most inclusive graphic element.
- Completeness - Within a part or unit, enter the letter for the most inclusive graphic element first.
- Encircled elements - If a character has more than 5 elements, exclude elements totally encircled by a surrounding unit).
- Stroke unity - Do not code a letter for an element that retraces part of another element. But do code for each stroke as a unit.
- Exceptions:
- Frequently used characters - Use simplified input codes (including letters for the first and last elements) for certain common characters.
- Primary input elements - Always enter the following elements first, even if they are not first in traditional calligraphic sequence:
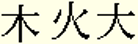
- Irregular elements - Use X to code for elements not represented by any of the 24 letters defined in standard TC coding.
Note: When you search the E-Dictionary by phonetic input code, you can apply the initial Latin script letter assigned to a graphic element in the TC input code (see table above) as a TC qualifier.
Input codes for punctuation, special characters, and roman punctuation
To enter the characters and punctuation listed in the following table using one of the CJK Input Method Editors, type the corresponding codes.
| Character or punctuation | Description | Input code |
|---|---|---|
 |
Center dot | vc |
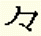 |
Character repetition (Kanji kurikaeshi kigo) | vk |
 |
Close angle bracket | v> |
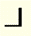 |
Close bracket | v] |
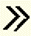 |
Close double angle bracket | v' |
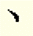 |
Comma | v, |
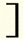 |
Roman close bracket | ] |
 |
Roman colon | : |
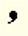 |
Roman comma | , |
 |
Roman hyphen | - |
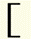 |
Roman open bracket | [ |
 |
Roman period | . |
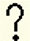 |
Roman question mark | ? |
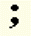 |
Roman semicolon | ; |
 |
Roman slash | / |
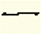 |
Long vowel (Choon kigo) | vl ("ell") |
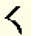 |
Open angle bracket | v< |
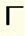 |
Open bracket | v[ |
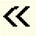 |
Open double angle bracket | v" |
 |
Period | v. |
 |
Phrase repetition (ditto mark) | vd |
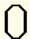 |
Zero | vz |
Note: For searching purposes, CJK punctuation and Latin punctuation are normalized; that is, you can enter punctuation either way and find the same records.