Catalog using Arabic scripts
About using Arabic scripts
Cataloging
Use Arabic script data for cataloging items in languages that use the script (for example, besides Arabic, Persian, Urdu, and Azerbaijani). Use Arabic script data the same way you use other non-Latin script data in the client.
See Work with international records and Guidelines for contributing non-Latin script bibliographic records to WorldCat for details specific to non- Latin scripts. See also general procedures describing how to:
Authorities
Arabic scripts can also be used to add variant name headings to authority records.
Tools for using non-Latin scripts
Specific tools for using Arabic scripts
- Automatically transliterate existing romanized data (Latin script equivalent) into Arabic script data for Arabic or Persian records:
- Use Edit > Transliterate > Arabic [or Persian] to transliterate selected data in a record.
- Set an option (for bibliographic records only) in Tools > Options > International to auto-transliterate Arabic and/or Persian WorldCat records when you download them interactively.
- Toggle alignment for Arabic or Hebrew script data right-to-left or left-to-right using View > Align Right (Default: Right-to-left).
- Use Unicode formatting characters to control correct display of bidirectional data in Arabic and Hebrew records.
Other tools to help with non-Latin scripts in general
- MARC-8 character verification (Edit > MARC-8 Characters > Verify) - Verify characters separately from record validation
- Link/unlink (Edit > Linking Fields > Link [or Unlink]) - Visually link or unlink non-Latin script data fields with equivalent Latin script (romanized) data fields (bibliographic records only)
- Export options for data fields (Tools > Options > International) - Determine (for bibliographic records only):
- Whether to export both equivalent Latin script (romanized) data and non-Latin script data or only one or the other
- Position of data if you export both Latin and non-Latin script data
- Sort order
- Export and import using UTF-8 Unicode or MARC-8 character sets. The UTF-8 Unicode option allows you to work with non-MARC-8 characters in the client for your local records (settings for export are in Tools > Options > Export, click Record Characteristics, and settings for import are in File > Import Records, click Record Characteristics).
Arabic script entry and character sets
Script entry methods
- If your system default language is not Arabic, you can install the Arabic language (in various forms) in Windows. When you install Arabic, Windows provides an input keyboard for entering Arabic script. See more about input methods for languages that use non-Latin scripts.
- OCLC provides an alternative Arabic script keyboard developed for RLIN21 cataloging software. You can download the Arabic keyboard.
RLIN21 keyboards include characters specific to each script (covering multiple languages that use Arabic script), whereas Microsoft keyboards include script characters specific to a single language.
Character sets supported
The client supports the following basic and extended Arabic character sets defined in MARC 21 Specifications for Record Structure, Character Sets, and Exchange Media for entering data in records and for entering WorldCat search terms.
- 33(hex) [ASCII graphic: 3] = Basic Arabic
- 34(hex) [ASCII graphic: 4] = Extended Arabic
Script identifiers in bibliographic records
The client adds the following data to c of field 066 in Arabic records to indicate the presence of Arabic characters:
- (3 (Basic Arabic)
- (4 (Extended Arabic)
Transliterate romanized data in Arabic or Persian records into Arabic script
The client provides two methods of automatic transliteration to help you create Arabic script in existing records that have romanized data only:
- Use Edit > Transliterate > Arabic [or Persian] to transliterate romanized data in selected fields of a displayed record.
- Set an option (for bibliographic records only) in Tools > Options > International to auto-transliterate existing romanized data in all Arabic and Persian records retrieved interactively from WorldCat (records with language code ara or per and no field 066). Also, select the fields to auto-transliterate.
Transliterate selected fields in a record
- Display a bibliographic, authority, or constant data record containing romanized Arabic or Persian data.
- Place the cursor in a field you want to transliterate into Arabic or Persian script.
Or
Select multiple fields containing romanized data. If you select parts of fields, the client transliterates the entire field(s). - When you are finished, perform one of the following actions:
- Click Edit > Transliterate > Arabic or press <Alt><E><T><A>.
- Click Edit > Transliterate > Persian or press <Alt><E><T><P>.
- Right-click the field and then click one of the following on the pop-up menu:
- Transliterate > Arabic
- Transliterate > Persian
Note: Although you can transliterate into Arabic or Persian while working offline (you do not need to be logged on to the OCLC system), your workstation must have an Internet connection.
Auto-transliterate WorldCat records retrieved interactively (bibliographic records only)
- Navigate to Tools > Options or press <Alt><T><O>.
- Click the International tab.
- Select one of the following check boxes:
- Auto-transliterate Arabic fields
- Auto-transliterate Persian fields
- (Optional) Select fields to auto-transliterate:
- In the International window, select one of the following check boxes:
- Auto-transliterate Arabic fields
- Auto-transliterate Persian fields
- Click Choose Fields to open the Choose Fields to Auto-Transliterate window.
- Click to select or deselect check boxes next to fields 1XX through 8XX (X = any valid tag number). By default, Fields 1XX through 8XX are selected.
- Click OK to save your settings or Cancel to cancel changes. You are returned to the International window.
- In the International window, select one of the following check boxes:
- When you are finished, perform one of the following actions:
- Click Close or press <Enter> to apply the settings and close the window.
- Click Apply to apply the settings without closing the window.
- Click Cancel to cancel changes you made.
 .
.
Results of transliteration and auto-transliteration
The client:
- Transliterates the romanized data word by word, independently of context.
Note: If context other than that of letters within a word is a factor in the appearance of the Arabic script text, you may need to edit the transliteration. See also caution below. - Creates an identical field with the same tag number (for example, two 245 tags) to contain the transliterated Arabic script.
- Places the Arabic script field above the associated romanized data field.
- Links the pair of associated fields with a bracket.
- If auto-transliterated (option for bibliographic records only, selected in Tools > Options > International), marks transliterated fields with the symbol .
Caution: Transliteration of Arabic handles the following characters incorrectly. Revise the characters manually.- The final character taa' marbuta preceded by hamza transliterates incorrectly as haa'.
- When 'alif maksura is followed by a period, the transliteration omits 'alif maksura.
- 'Alif laam followed by 'alif madda transliterates incorrectly as 'alif laam 'alif.
- Hyphens are incorrectly deleted in transliterated text.
- When laam kasra is followed by siin or jiim, the transliteration omits siin or jiim.
- Laam kasra followed by Haa' transliterates incorrectly as haa'.
- When two laams are followed by capital A (where the first laam is a preposition), the transliteration omits 'alif hamza. However, laam followed by lowercase "a" transliterates correctly as laam 'alif.
- When laam hyphen is followed by damma, the transliteration omits 'alif hamza.
Basis of transliteration
The client transliterates romanized data based on the rules for Arabic and for Persian given in the ALA-LC Romanization Table on the Library of Congress website.
Align Arabic or Hebrew script data for display and print
By default, the client displays (and prints) records with Arabic or Hebrew script aligned to the right. To toggle between displaying these scripts right-to-left or left-to-right:
To toggle alignment for all Arabic or Hebrew script data in the current record, click View > Align Right or press <Alt><V><I>. By default, data aligns to the right for display and printing. The Align Right icon next to the command on the View menu is active (highlighted) when Align Right is selected. The icon is inactive (grayed out) when Align Right is cleared.
To toggle data alignment in the current field, right-click a field and then click Right-to-Left Reading Order on the pop-up menu. The client changes the alignment of the Arabic or Hebrew script data only in the current field.
Use Unicode formatting characters to control bidirectional data
Enter Unicode formatting characters in Arabic, Persian, and Hebrew records to correctly display left-to-right multiple-digit numbers and punctuation, including brackets, hyphens, internal spaces, etc., within a field of right-to-left script data.
- Export/import using UTF-8 Unicode character set - Unicode formatting control characters are retained as is in Arabic, Persian, and Hebrew records exported or imported using the UTF-8 Unicode character set, along with other non-MARC-8 Unicode characters.
- Export/import using MARC-8 character set - The Unicode formatting characters are retained in Numeric Character Reference (NCR) format in records exported or imported using the MARC-8 character set, along with other non-MARC-8 characters.
More information:
- See the Bidirectional Algorithm report on the Unicode website for details.
- See more about selecting a character set for exporting and importing bibliographic records in the client.
To insert a Unicode control character:
- Click to locate the cursor in the position where you want to insert a formatting control number.
- Right-click in the field and then click Insert Unicode Control Character or press the keystrokes shown in step 3.
- Click one of the following characters or press the keystroke shortcuts:
- LRM Left-to-Right Mark or press <Alt><R><L>
- RLM Right-to-Left Mark or press <Alt><R><R>
- ZWJ Zero Width Joiner or press <Alt><R><J>
- ZWNJ Zero Width Non-Joiner or press <Alt><R><N>
- LRE Start of Left-to-Right Embedding or press <Alt><R><S>
- RLE Start of Right-to-Left Embedding or press <Alt><R><T>
- LRO Start of Left-to-Right Override or press <Alt><R><A>
- RLO Start of Right-to-Left Override or press <Alt><R><F>
- PDF Pop Directional Formatting or press <Alt><R><P>
Tip for one-step entry: Create a text string using Tools > Text Strings; click Add and enter one of the characters listed above using the right-click menu. Then use the Text Strings quick tool on the toolbar to enter the character.
Or
Assign the text string to a keystroke shortcut. Enter the character by pressing the keystroke.
Example
To control the display of the data 742[1981 or 1982] that you enter in field 260 c of a bibliographic record that is preceded and followed by Arabic script data:
- Click to locate the cursor in field 260 c.
- Right-click in the field, click Insert Unicode Control Character in the pop-up menu, and then click LRE Start of Left-to-Right Embedding.
- Enter the data string, 742[1981 or 1982], immediately following the character.
- Without moving the cursor, right-click in the field again. In the pop-up menu, click Insert Unicode Control Character and then click PDF Pop Directional Formatting.
Use Arabic definite article in Arabic script searches
Always include the Arabic definite article ال ('alif laam) on words in a keyword search.
Indexing for Arabic script searches
Notes on searching
- Use word or phrase search indexes and word or phrase browse indexes.
- Word searches find the data string you enter anywhere in the indexed field. Phrase searches find the data string starting with the first character in a field or subfield and including each character in exact order. Browsing scans an index for the closest match to the character string followed by any other data.
- If you use qualifiers to limit searches, enter them using Latin script.
- Do not use derived searching.
- Do not use truncation (asterisk (*) at the end of a search term). You can use browsing for automatic truncation (enter only as many characters as needed for a match without using an asterisk at the end).
- If you want to retrieve all Arabic script records or see sample records, use the "character sets present" search index (label vp:) with the assigned code ara. To find all Arabic script records, enter vp:ara as a Command Line Search only.
Note: If a search for all Arabic script records alone retrieves too many WorldCat records (limit 1,500 records), you must limit the search and try again (e.g., vp:ara/1991-2; vp:ara and la:per; etc.).
See general procedures and search techniques for searching WorldCat.
Arabic character indexing specifics
The following table shows Arabic characters grouped and indexed together as if they are the same character (the characters are "normalized").
Enter any character of a group of normalized characters in a search and retrieve results for all characters in the group.
Images and names of characters indexed the same are in columns 3 and 4, opposite the character with which they are grouped/indexed.
| Character | Character name | Other characters indexed the same | |
|---|---|---|---|
| Character | Character name | ||
| ا | 'alif | 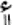 |
double 'alif with hamza above |
| آ | 'alif with madda above | ||
| أ | 'alif with hamza above | ||
| إ | 'alif with hamza below | ||
| ٱ | 'alif wasla | ||
| ٲ | 'alif with wavy hamza above | ||
| ٳ | 'alif with wavy hamza below | ||
| ت | taa' | ة | taa' marbuta |
| ټ | taa' with ring | ||
| ٽ | taa' with three dots above | ||
| ح | Haa' | ځ | Haa' with hamza above |
| ڂ | Haa' with two dots vertical above | ||
| څ | Haa' with three dots above | ||
| د | daal | ډ | daal with ring |
| ڊ | daal with dot below | ||
| ڋ | daal with dot below and small Taa' | ||
| ڏ | daal with three dots above downwards | ||
| ڐ | daal with four dots above | ||
| ر | raa' | ڒ | raa' with small v |
| ړ | raa' with ring | ||
| ڔ | raa' with dot below | ||
| ڕ | raa' with small v below | ||
| ږ | raa' with dot above and below | ||
| ڗ | raa' with two dots above | ||
| ڙ | raa' with four dots above | ||
| س | siin | ښ | siin with dot below and dot above |
| ڛ | siin with three dots below | ||
| ش | shiin | ڜ | shiin with three dots below and three dots above |
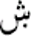 |
shiin with dot below | ||
| ص | Saad | ڝ | Saad with two dots below |
| ڞ | Saad with three dots above | ||
| ض | Daad | 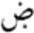 |
Daad with dot below |
| غ | ghayn | 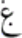 |
ghayn with dot below |
| ط | Taa' | ڟ | Taa' with three dots above |
| ع | ayn | ڠ | ayn with three dots above |
| ف | faa' | ڡ | dotless faa' |
| ڢ | faa' with dot moved below | ||
| ڣ | faa' with dot below | ||
| ڥ | faa' with three dots below | ||
| ق | qaaf | ڧ | qaaf with dot above |
| ڨ | qaaf with three dots above | ||
| ك | kaaf | ڪ | swash kaaf |
| ګ | kaaf with ring | ||
| ڬ | kaaf with dot above | ||
| ڮ | kaaf with three dots below | ||
| گ | gaf | ڰ | gaf with ring |
| ڲ | gaf with two dots below | ||
| ڴ | gaf with three dots above | ||
| ل | laam | ڵ | laam with small v |
| ڶ | laam with dot above | ||
| ڷ | laam with three dots above | ||
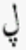 |
laam with three dots below | ||
| ن | nuum | ڼ | nuun with ring |
| ڽ | nuun with three dots above | ||
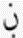 |
nuun with dot below | ||
| ں | nuun ghunna | ||
| ه | haa' | ھ | haa' doachashmee |
| ۀ | haa' with hamza above | ||
| و | waaw | ؤ | waaw with hamza above |
| ۊ | waaw with two dots above | ||
| ۄ | waaw with ring | ||
| ي | yaa' | ئ | yaa' with hamza above |
| ى | 'alif maksura | ||
| ۍ | yaa' with tail | ||
| ێ | yaa' with small v | ||
| ے | yaa' barree | ||
| ۓ | yaa' barree with hamza above | ||
| ۆ | ie | ۅ | kirgiz oe |